
La synthèse des protéines - 1e L
Classe:
Première
Introduction
Les cellules eucaryotes animales comme végétales, contiennent toutes dans leur noyau des chromosomes qui sont le support de l'hérédité.
Ces chromosomes contiennent une molécule responsable de la formation des protéines in vivo.
Les molécules d'acides contenues dans le noyau sont qualifiées d'acides nucléiques.
Nous verrons dans la leçon la structure et la composition chimique de ces acides nucléiques, la réplication et en fin le processus de la synthèse des protéines.
I. Localisation des acides nucléiques dans la cellule
Pour mettre en évidence les acides nucléiques $(ADN$ et $ARN)$ dans la cellule, deux colorants (Pyronine et vert de méthyle) et deux enzymes $(ARN$ase et $ADN$ase$)$ sont utilisés : c'est le test de Brachet.
La pyronine colore en rose l$ARN$ et le vert de méthyle colore l$ADN$ en vert. L'$ARN$ase est une enzyme qui détruit l$ARN$ et l$ADN$ase, une enzyme qui détruit l$ADN.$
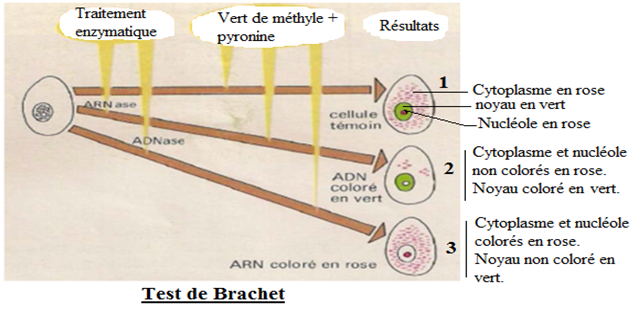
a. Analyse des résultats (test de Brachet)
Les cellules du lot 1 après traitement à la pyronine et au vert de méthyle, il y a coloration en rose du cytoplasme et du nucléole et coloration en vert du noyau.
Les cellules du lot $2$, après avoir été traitées avec ces deux colorants puis avec l'$ARN$ase, il y a coloration en vert du noyau et non coloration en rose du cytoplasme et du nucléole.
Quant aux cellules du lot $3$, après traitement avec ces deux colorants (pyronine et vert de méthyle) puis traitement avec l'$ADN$ase, il y a coloration en rose du cytoplasme et du nucléole et non coloration du noyau en vert.
b. Conclusion
D'après l'analyse des résultats du test de Brachet, on en déduit que l'$ADN$ est localisé seulement dans le noyau et l'$ARN$ est localisé aussi bien dans le nucléole que dans le cytoplasme.
II. La structure et la composition chimique des acides nucléiques
1. La structure et la composition chimique de l'$ADN$
a. Structure
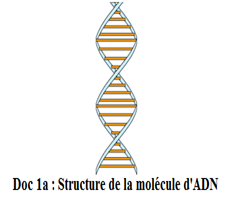
L'Acide désoxyribonucléique $(ADN)$ est le principal constituant des chromosomes.
L'analyse physico-chimique par diverses techniques $($diffraction aux rayons $X)$ a permis à Watson et Crick de montrer en $1953$ que la molécule d'$ADN$ a la structure d'une double hélice avec deux brins enroulés l'un autour de l'autre : on dit que l'$ADN$ est bicaténaire.
b. Composition chimique
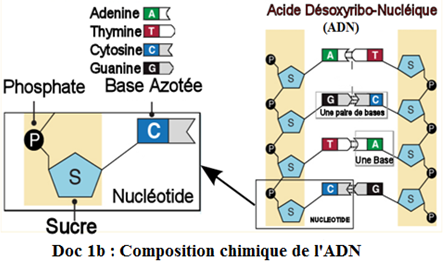
Si on déroule la molécule d'$ADN$, elle prend la forme d'une échelle dont les montants (brins) sont constitués de désoxyribose (sucre à 5 atomes de carbone) et d'acide phosphorique.
Les barreaux sont formés par des bases azotées au nombre de $4$ : l'adénine $(A)$, la thymine $(T)$, la guanine $(G)$ et la cytosine $(C)$ qui reliés deux à deux par des liaisons hydrogènes.
L'adénine est toujours liée à la thymine $(A-T)$ et la cytosine liée à la guanine $(C-G)$ : on dit que les bases azotées sont complémentaires.
L'adénine et la guanine sont appelées bases puriques tandis que la cytosine et la thymine sont des bases pyrimidiques.
Chaque brin d'$ADN$ est constitué d'une succession de nucléotides.
$L'ADN$ est donc un polymère de nucléotides.
Un nucléotide est formé d'une base azotée, d'un sucre (ici le désoxyribose) et d'un acide phosphorique.
L'ordre de succession des nucléotides différent d'un individu à un autre (sauf les vrais jumeaux), constitue l'information génétique.
L'association d'une base azotée et d'un sucre forme un nucléoside.
Un gène est fragment d'$ADN$ qui conditionne la transmission et l'expression d'un caractère héréditaire.
2. Structure et composition chimique de l'$ARN$
a. Structure
Contrairement à l'$ADN$, l'acide ribonucléique $(ARN)$ est constitué d'un seul brin plus ou moins replié sur lui-même (linéaire) : on dit que la molécule d'$ARN$ est monocaténaire.
b. Composition chimique
D'une façon générale, l'$ARN$ a quelques ressemblances avec l'$ADN$ : il est formé d'un sucre, de bases azotées et d'acide phosphorique.
$L'ARN$ est formé comme l'$ADN$ d'un enchainement de nucléotides $($base azotée $+$ sucre $+$ acide phosphorique$).$
Dans l'$ARN$ aussi, l'association d'une base azotée et d'un sucre forme un nucléoside. Les différences avec l'$ADN$ sont les suivantes :
$-\ $Dans l'$ARN$, le sucre est le ribose
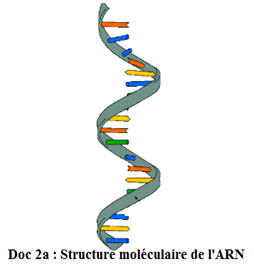
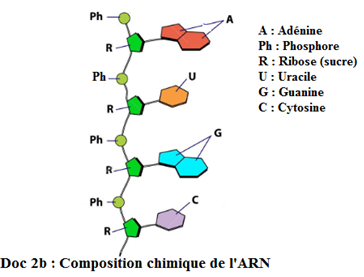
$-\ $L'uracile $(U)$ remplace la thymine $(T).$
$-\ $L'$ARN$ est formé d'un seul brin (monocaténaire).
Remarque :
Il existe $3$ sortes d'$ARN$ :
$-\ L'ARN$ messager $(ARNm)$
$-\ L'ARN$ de transfert $(ARNt)$
$-\ L'ARN$ ribosomal $(ARNr).$
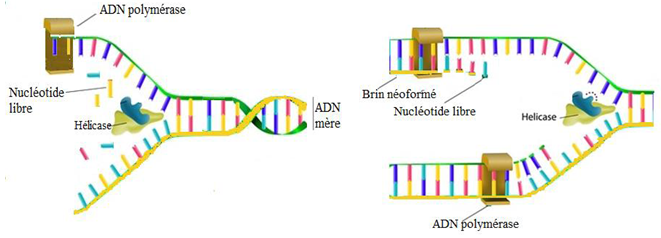
III. La réplication de $L'ADN$
La réplication débute à plusieurs endroits de la molécule d'$ADN$ et progresse sur les deux brins de la molécule initiale qui sont écartés par une enzyme appelée hélicase créant ainsi des « yeux de réplication ».
Après écartement de la molécule, l'$ADN-$polymérase associe les nucléotides libres du noyau à ceux des brins initiaux par le jeu de la complémentarité : c'est l'initiation.
L'écartement des deux brins initiaux continus et les deux brins en cours de formation (brins néoformés) s'allongent également : c'est l'élongation.
Les « yeux de réplications » progressent en sens inverse et la réplication sera terminée quand tous les yeux se rejoignent.
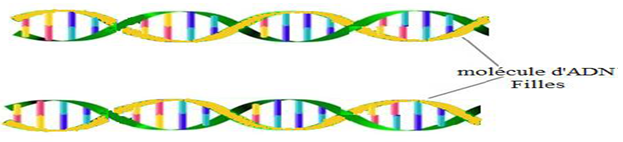
A la fin de la réplication (ou terminaison), on obtient deux molécules d'$ADN$ filles qui ont chacune un ancien brin hérité de la molécule-mère et un brin nouvellement formé (brin néoformé).
Ainsi une moitié de la molécule initiale est conservé : on dit que le mécanisme de la réplication est semi-conservatif.
IV. La synthèse des protéines
La séquence de l'$ADN$ d'un gène formée de nucléotides, contient le message nécessaire à la synthèse d'une protéine.
Une protéine est une succession d'acides aminés dont le nombre est supérieur à $100.$
Lorsque le nombre d'acides aminés est inférieur à $100$, on parle de polypeptide.
Les acides aminés sont unis les uns des autres par les liaisons peptidiques.
L'$ADN$ est écrit en « langage nucléotides » alors que la protéine est écrite en « langage acides aminés ».
Il doit exister une correspondance entre les nucléotides et les acides aminés.
Cette correspondance est le code génétique.
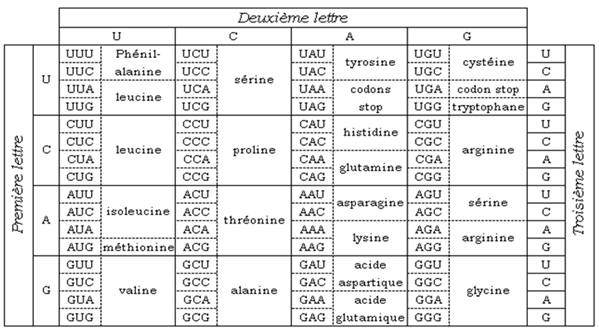
1. Le code génétique
Des expériences ont démontré que la « lecture » de l'information génétique se fait suivant un cadre de longueur fixe, constitué de $3$ nucléotides : un triplet de nucléotides (ou codon) code pour un acide aminé.
Le code génétique est donc le système de correspondance entre un triplet de nucléotides et un acide aminé.
Comme il existe $4$ nucléotides et qu'un codon est formé de $3$ nucléotides, on dénombre $64$ triplets différents $(43).$
Au total nous avons $20$ acides aminés, or les codons sont au nombre de $64.$
Cela signifie d'une part que plusieurs codons peuvent coder pour un seul acide aminé : c'est la redondance du code génétique.
D'autre part on constate que dans le tableau du code génétique 3 codons ne codent pour aucun acide aminé : ils sont dits « codons-stop ou « codons non-sens ».
Le code génétique est commun à l'ensemble des êtres vivants sauf quelques exceptions : on dit que le code génétique est universel.
2. La transcription
Chez les eucaryotes, l'$ADN$ est toujours localisé dans le noyau cellulaire, séparé du cytoplasme par l'enveloppe nucléaire.
$L'ADN$ étant une grosse molécule ne peut donc sortir du noyau or la synthèse des protéines s'effectue dans le cytoplasme.
Dans le noyau, s'effectuera donc un copiage de l'$ADN$ en une molécule de petite taille qui porte le message contenu dans l'$ADN$ : l'$ARN$ messager $(ARNm).$
Cette transformation de l'$ADN$ en $ARNm$ dans le noyau, est appelé la transcription.
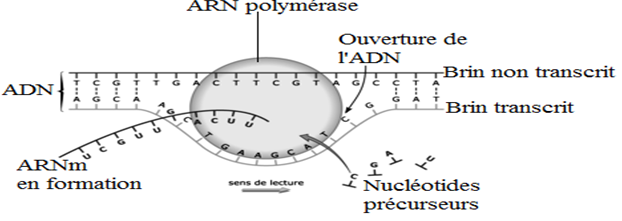
Cette transcription nécessite l'action d'une enzyme : l'$ARN-$polymérase.
Au fur et à mesure de sa progression le long de l'$ADN$, l'$ARN-$polymérase incorpore des nucléotides libres, présents dans le noyau par complémentarité avec l'un des brins de l'$ADN$ : $G$ se place en face de $C$, $C$ en face de $G$, $A$ en face de $T$ et $U$ en face de $A.$
Le brin d'$ARN$ ainsi formé est complémentaire au brin d'$ADN$ qui a servi de matrice, appelé brin transcrit.
Par ailleurs, la séquence de l'$ARNm$ est identique à celle du brin non transcrit (à la seule différence du nucléotide $U$ qui, sur l'$ARN$, occupe la place du nucléotide $T$ sur le brin non transcrit).
Remarque :
Le brin transcrit est également appelé brin non codant et le brin non transcrit est aussi appelé brin codant.
A la fin de la transcription, l'$ARNm$ ainsi formé, passe par les pores nucléaires et se retrouve dans le cytoplasme où il sera « traduit » en protéine.
3. Les étapes de la traduction
La synthèse des protéines comprend deux grandes étapes : la transcription et la traduction.
La traduction est le passage de l'$ARNm$ à la protéine.
Elle a lieu dans le cytoplasme de la cellule. La traduction nécessite la présence de ribosomes $($qui lisent l'$ARNm$ dans le sens $5'$ vers $3')$, des $ARNt$ (qui capturent les acides aminés du cytoplasme et les transportent jusqu'au ribosome) et l'$ARNm.$
La traduction se décompose en trois étapes :
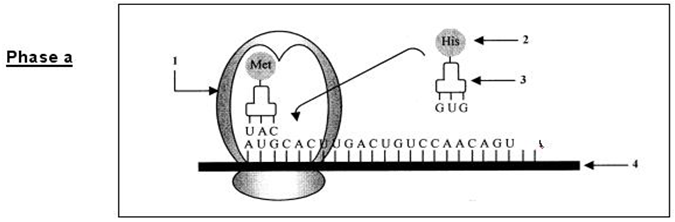
$\blacktriangleright\ $La phase d'initiation : La traduction commence toujours par un codon particulier de l'$ARNm$, le codon initiateur $AUG$ (codant pour la méthionine).
La petite sous-unité du ribosome se fixe à l'$ARNm$ au niveau du codon initiateur et à l'$ARNt$ portant la méthionine. Ensuite la grande sous-unité du ribosome s'ajoute à ce complexe et le ribosome est alors formé.
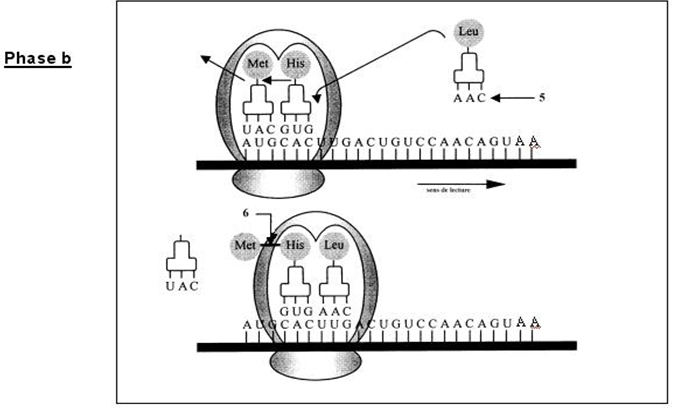
$\blacktriangleright\ $La phase d'élongation : Le ribosome se déplace sur l'$ARNm$ de triplet en triplet, en formant des liaisons peptidiques entre les acides aminés correspondant à chaque codon et à l'acide aminé précédent dans la chaîne polypeptidique.
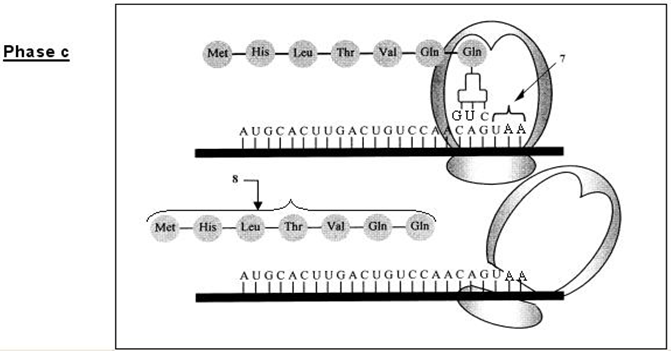
$\blacktriangleright\ $La phase de terminaison : La terminaison a lieu lorsque le ribosome rencontre sur l'$ARNm$ un codon-stop $(UAA\;,\ UAG\text{ ou }UGA).$
Il se produit alors une coupure entre la chaîne peptidique et le dernier $ARNt$ qui libère la protéine et les deux sous-unités du ribosome se séparent.
Un $ARNm$ peut être lu par plusieurs ribosomes à la fois.
Dans ce cas les ribosomes forment un polysome (ou polyribosomes).
Remarque : les mutations
Une mutation est une modification de la séquence des nucléotides de l'$ADN.$
On distingue différents types de mutations :
$\surd\ $La substitution : c'est le remplacement d'un nucléotide par un autre nucléotide.
Les mutations par substitution sont silencieuses, si elles n'entrainent pas le changement d'acides aminés dans la protéine.
Elles sont neutres si elles entrainent le remplacement d'un acide aminé par un autre sans que cela ait de conséquence sur le fonctionnement de la protéine.
Elles sont faux-sens si elles entrainent le remplacement d'un acide aminé par un autre et que cela induit une modification du fonctionnement de la protéine. Si la mutation par substitution génère un codon-stop, elle est appelée mutation non-sens.
$\surd\ $La délétion : Correspond à une perte d'un ou de plusieurs nucléotides.
$\surd\ $L'addition ou insertion : C'est un ajout d'un ou de plusieurs nucléotides.
Ajouter un commentaire